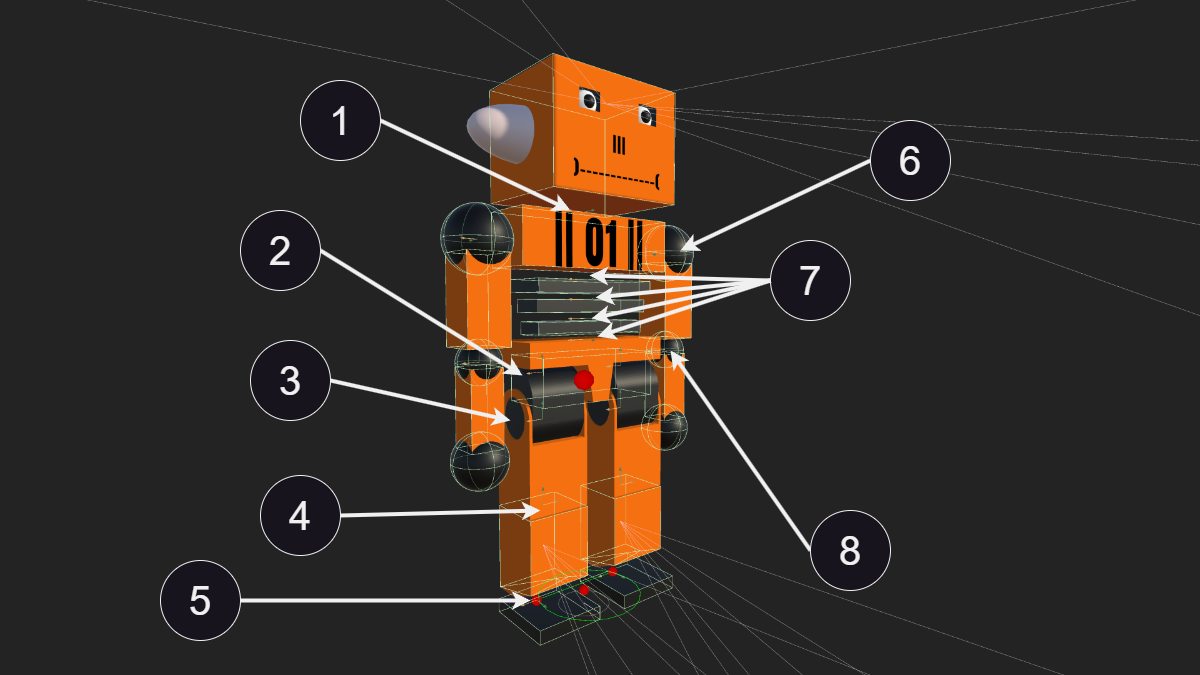
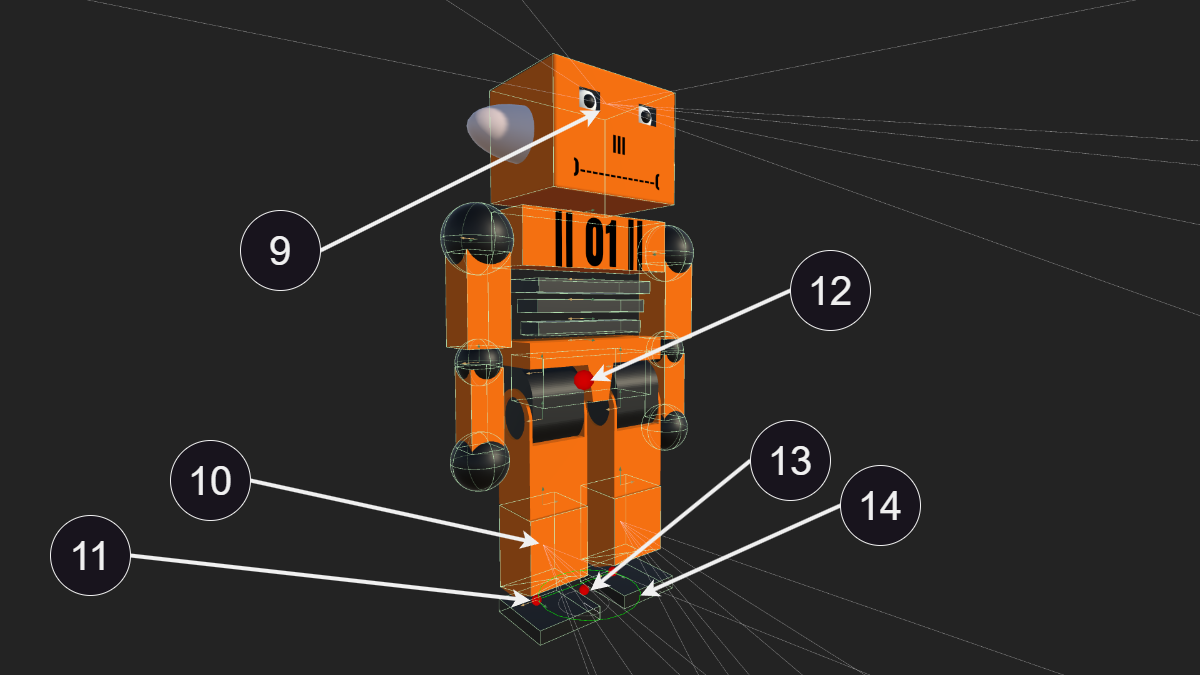
Type d'Algorithme et Hyperparamètres
Dans cette section, les range de valeurs utilisé seront indiqué en bleu.
Type d'Algorithme
PPO
Il existe plusieurs types d'algorithmes d'entraînement :
- PPO : Utilise l'apprentissage sur la politique, ce qui signifie qu'il apprend
sa fonction de valeur à partir des observations faites par la politique actuelle explorant
l'environnement.
- SAC : Utilise l'apprentissage hors politique, ce qui signifie qu'il peut
utiliser les observations faites lors de l'exploration de l'environnement par des politiques
antérieures. SAC utilise cependant beaucoup plus de ressources.
J'ai commencé par utiliser les algorithmes PPO car ce sont ceux par défaut et le SAC avait des
problèmes de librairies. Cependant, après quelques modifications, j'ai réussi à utiliser les
algorithmes SAC.
L'apprentissage avec SAC est très rapide et fonctionne très bien pour des actions simples. Cependant,
il n'est pas possible de suivre visuellement l'évolution de l'agent étant donné les ressources
demandées. J'ai également constaté de moins bonnes performances sur les apprentissages complexes et
une plus grande tendance à exploiter la moindre mécanique défaillante.
Je suis donc repassé sur les algorithmes PPO car ils sont plus stables dans l'apprentissage et
j'utilise le SAC uniquement pour tester une reward ou une action simple afin de gagner du temps.
Les Hyperparamètres
Dans le domaine de l'apprentissage par reinforcement, les hyperparamètres sont des réglages externes
à un modèle de machine learning, qui influencent le processus d'apprentissage. Contrairement aux
paramètres internes d'un modèle, qui sont appris pendant l'entraînement, les hyperparamètres doivent
être définis avant le début de l'entraînement.
Lorsque vous utilisez Unity ML-Agents pour entraîner des agents intelligents, il est essentiel de
bien comprendre et régler les hyperparamètres pour obtenir de bons résultats. Voici quelques-uns des
hyperparamètres les plus importants dans Unity ML-Agents avec les valeurs que j'ai utilisées pour
mon modèle :
1. Learning Rate (Taux d'apprentissage)
1×10−4 - 3×10−4
Le learning rate détermine la vitesse à laquelle le modèle met à jour ses paramètres internes en
fonction des erreurs observées pendant l'entraînement. Un taux d'apprentissage trop élevé peut
rendre l'apprentissage instable, tandis qu'un taux trop bas peut le rendre trop lent. Au début de
l'apprentissage, l'agent commence avec un learning rate de 0.0003 et termine avec 0.0001. Cette
valeur a une décroissance linéaire pour chaque apprentissage.
2. Batch Size (Taille du lot)
4096
La batch size correspond au nombre d'exemples de données que le modèle traite avant de mettre à jour
ses paramètres internes. Des lots plus grands peuvent rendre l'apprentissage plus stable, mais
nécessitent plus de mémoire. La valeur de 4096 m'a semblé être le meilleur compromis entre les
ressources nécessaires et la stabilité de l'apprentissage.
3. Buffer Size (Taille du buffer)
40960
Le buffer size détermine combien de pas de temps sont stockés avant que le modèle ne mette à jour ses
paramètres. Une taille de buffer plus grande peut aider à stabiliser l'apprentissage, mais augmente
également les besoins en mémoire. Une valeur de 40960 a été utilisée, ce qui est le double de la
valeur par défaut, réduisant le nombre d'agents entraînés simultanément.
4. Gamma
0.995 - 0.998
Gamma est le facteur de discount, qui détermine l'importance des récompenses futures par rapport aux
récompenses immédiates. Un gamma élevé signifie que l'agent accorde plus d'importance aux
récompenses futures. Une valeur oscillante entre 0.995 et 0.998 a été utilisée.
5. Lambda
0.95
Lambda est utilisé dans le calcul de l'avantage généralisé (GAE) pour contrôler le biais-variance
dans les estimations de l'avantage. Un lambda plus élevé peut réduire le biais mais augmenter la
variance. Dans notre cas, cette valeur est de 0.95, ce qui est le paramètre par défaut.
6. Beta
0.001 - 0.005
Dans les algorithmes de politique, Beta est utilisé pour l'exploration. Un Beta élevé favorise
l'exploration de nouvelles actions, tandis qu'un Beta bas favorise l'exploitation des actions
connues. Une valeur Beta élevée (0.005) permet à l'agent d'apprendre rapidement à marcher.
Cependant, garder une valeur aussi élevée une fois les premiers pas réalisés est contre-productif.
Afin de pouvoir marcher, l'agent doit réaliser un enchaînement de mouvements complexes. Si un seul
de ces mouvements est mal exécuté, l'agent perd l'équilibre et chute. Si pour chacun des 39 muscles
l'agent a un pourcentage trop élevé de réaliser une action aléatoire (découverte), il a peu de
chances de parvenir à réaliser un mouvement dépassant son précédent record. Donc cette valeur est
mise à 0.005 jusqu'à ce que l'agent réalise ses trois premiers pas, puis est mise à 0.001. Cette
valeur a une décroissance linéaire pour chaque apprentissage.
7. Epsilon
0.1 - 0.6
Epsilon correspond au seuil acceptable de divergence entre l'ancienne et la nouvelle politique lors
de la mise à jour de la descente de gradient. Définir cette valeur sur une valeur faible entraînera
des mises à jour plus stables, mais ralentira également le processus de formation. J'ai trouvé
qu'une très forte valeur (0.6) est nécessaire pour les premiers pas et permet de grandement
accélérer l'apprentissage, mais que cette valeur doit être abaissée à 0.1 dès que les premiers pas
ont été réalisés. Le problème avec le premier pas est que l'agent a peu de chances de le réaliser au
hasard et ne fait que peu de points avant cela. Comme pour l'hyperparamètre Beta, l'agent a peu de
chances de parvenir à faire son premier et second pas uniquement au hasard. Il est donc préférable
qu'il puisse rapidement mettre à jour son modèle une fois le premier et le second pas réalisés.
8. Num Layers (Nombre de couches)
4
Le nombre de couches dans le réseau neuronal détermine la profondeur du modèle. Des réseaux
plus profonds peuvent capturer des relations plus complexes, mais sont également plus
susceptibles de surajuster les données d'entraînement et de partir en overfitting. Pour mon
robot, j'ai commencé l'apprentissage avec 3 couches de 256 neurones. Mais ce qui semble le
mieux fonctionner est 4 couches de 256 neurones avec une couche possédant un dropout de 0.5.
Le dropout consiste à désactiver aléatoirement une fraction des neurones pendant
l'entraînement et permet de rendre le modèle plus robuste en le forçant à ne pas se reposer
uniquement sur un chemin neuronal. L'ajout du dropout a été fait à la base pour éviter
l'overfitting (surapprentissage), mais j'ai constaté que l'agent apprenait bien plus
rapidement avec et gardait une meilleure stabilité.
Visualisation d'un model neuronale composé de 2 couches denses de
respectivement 2 et 3 neurones
9. Hidden Units (Unités cachées)
256
C'est le nombre de neurones par couche (Num layers). Le nombre d'unités cachées par couche dans le
réseau neuronal affecte la capacité du modèle à apprendre des représentations complexes des données
d'entrée. Plus d'unités cachées augmentent la capacité de modélisation mais nécessitent plus de
données et de calculs. Les modèles testés avec plus de 256 neurones (512 et 1024) ont donné de bons
résultats au début, mais partent trop vite en overfitting et prennent trop de temps d'apprentissage.
Avec 128 neurones, l'agent apprend très vite, mais il se retrouve limité dans le nombre d'actions
qu'il peut apprendre.
10. num_epoch
3 - 6
num_epoch est le nombre de passages à travers le buffer d'expérience pendant la descente de
gradient. Diminuer cette valeur garantira des mises à jour plus stables, au prix d’un
apprentissage plus lent. J'utilise une valeur de 3 pour un entraînement normal et 6 quand je
dois faire des tests et que seul le temps d'apprentissage compte.
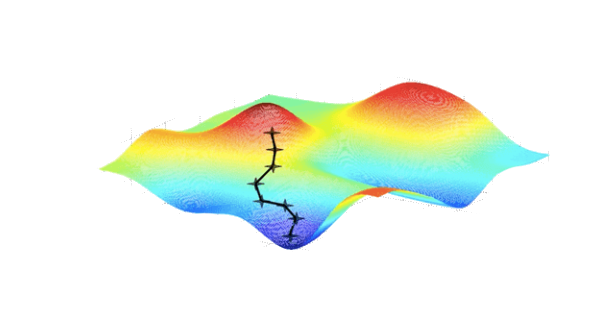
Visualisation de la descente de gradient, un algorithme d'optimisation
couramment utilisé en apprentissage automatique et en apprentissage par renforcement.
11. Fonction d'activation
ReLu
Normalement, Unity ne propose pas de modifier la fonction d'activation et utilise la fonction
ReLu (f(x)=max(0,x)).
ReLU (Rectified Linear Unit) f(x) = max(0, x)
ReLU est une fonction simple et efficace, définie comme le maximum entre 0 et l'entrée x.
Elle aide à atténuer les problèmes de gradient explosif ou disparaissant et introduit de la
sparsity dans le réseau, ce qui peut améliorer l'efficacité du modèle.
Swish f(x) = x · sigmoid(x)
Swish est définie comme le produit de l'entrée x et de la fonction sigmoïde de x. Swish est
une fonction lisse, offrant des gradients plus stables et pouvant améliorer les performances
et la vitesse de convergence dans certains contextes d'apprentissage.
Avantages de Swish
- Lissage : Fournit des gradients plus stables.
- Performance : Peut offrir de meilleures performances que ReLU dans certaines
applications.
- Flexibilité : Meilleure flexibilité dans l'apprentissage de relations complexes dans les
données.
Par manque de temps, je n'ai pas implémenté la fonction Swish (f(x)=x⋅sigmoid(x)) dans la
version finale. Mais j'ai cependant testé cette fonction qui semble donner de bons résultats
et vais sans doute poursuivre dans cette direction